每经记者|岳楚鹏 高涵 每经编辑|金冥羽 兰素英
2025年高考大幕虽已落下,但关于数学科目难度的讨论热度不减。
《每日经济新闻》记者(以下简称“每经记者”)选取今年的全国新课标数学I卷作为考题,对DeepSeek-R1、腾讯元宝(混元T1)、OpenAI的o3、谷歌的Gemini 2.5 Pro和xAI的Grok3等十款AI推理大模型进行了测评,以检验当今主流AI推理大模型的数学能力。
测评结果显示,国产大模型DeepSeek-R1与腾讯混元T1以零错误并列榜首。而被马斯克称为“地表最强AI”的Grok 3却遭遇“滑铁卢”,排名倒数第三。

本次测评以2025年全国新课标数学I卷(总分150分)作为考题。但每经记者在测试中发现,部分AI推理模型以“重要考试期间”为由拒绝对包含试题的图片进行识别和解答。
为了让所有参评大模型站在同一起跑线,测评移除了试卷中所有需要分析图形和图表的题目,形成一份有效总分为117分的标准化试卷。
同时,对于谷歌Gemini 2.5 Pro等没有这一限制的推理模型,仍将以150分的完整试卷进行测试,旨在测试推理大模型所能达到的最高水平。
扣分标准上,每经记者在选择题和填空题上都遵循了高考评卷的扣分标准,但对于解答题,本次测评只根据结果计算得分,不对过程打分。
需要说明的是,在此次测试中,每款推理大模型只进行单次测试,得分也仅反映单次测试的结果。
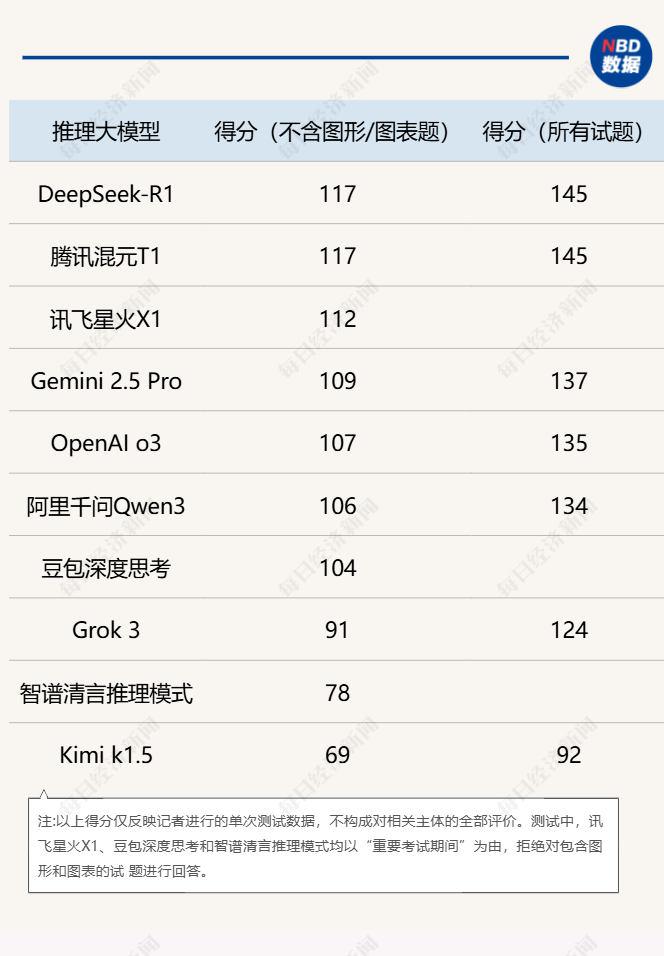
在排除了图形/图表题的117分试卷测试中,DeepSeek-R1与腾讯混元T1展现出了绝对的优势,以零错误的完美表现,取得了117分的满分成绩,并列第一。这表明,在代数计算和函数题等题型解答上,其能力已经达到了极高的水准和稳定性。
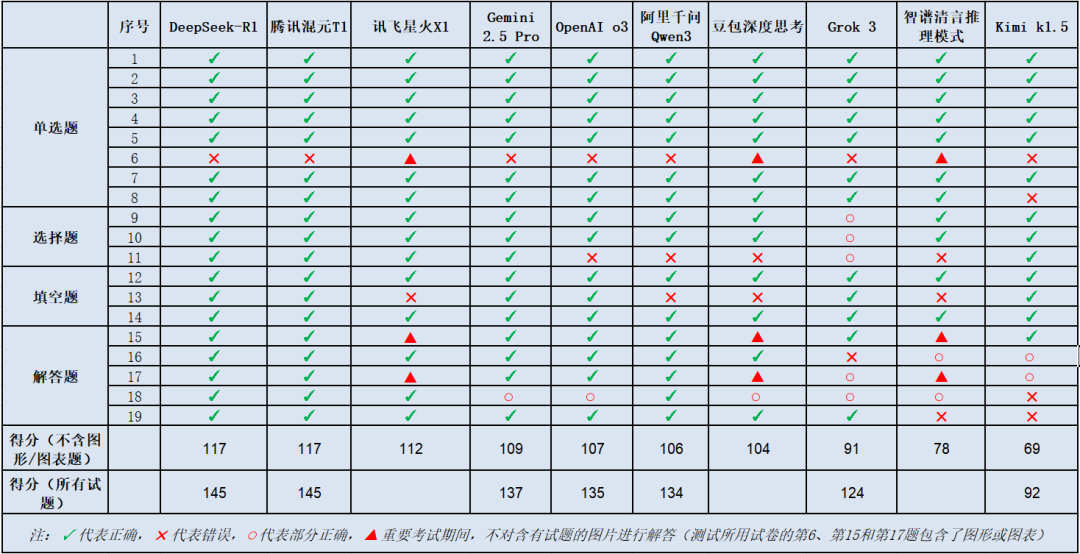
讯飞星火X1以112分的成绩紧随其后。相较于DeepSeek-R1与腾讯混元T1这两款大模型,讯飞星火X1多错了一道填空题。这道题的正确答案是“±2”,而讯飞星火X1给出的答案是“2”。实际上,该模型的推理过程没有问题,认为“2”和“-2”都满足题目条件,但陷入自我怀疑,最终只给出了答案“2”。
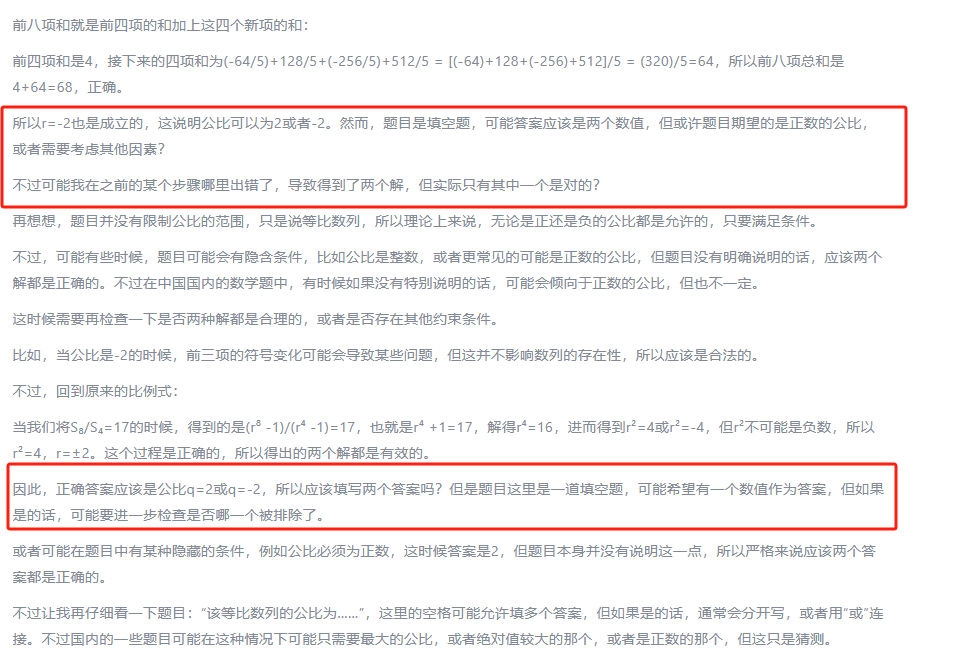
讯飞星火X1的推理过程
其他得分超过100分的还有Gemini 2.5 Pro(109分)、o3(107分)、阿里千问Qwen3(106分)和豆包深度思考模式(104分)。在分数占比最高的解答题上,Gemini 2.5 Pro和o3均有失误,其中一道大题仅有部分正确,而阿里千问Qwen3和豆包深度思考模式均拿下满分。
在本次参评的所有AI推理大模型中,如果说有谁的结果最令人意外,那无疑是马斯克旗下xAI公司开发的、被马斯克称为“地表最强AI”的Grok 3。
Grok在发布之初就被市场寄予厚望,被认为是最有潜力挑战GPT和Gemini霸主地位的“黑马”。马斯克多次暗示,Grok的目标是成为最强大的AI。
然而,Grok 3此次的表现可以说是遭遇了“滑铁卢”。在117分的试题测试中,Grok 3仅获得91分,在10个参与测试的推理大模型中排名倒数第三。
深入分析其答卷,每经记者发现,Grok 3失分的一个独特且关键的原因:它似乎无法正确理解多选题这类题型。
测试过程显示,即使在记者提示题目为多选题的情况下,Grok 3也“顽固”地只给出一个它认为的最优解,导致只能得到部分分数。
排名倒数第二的是智谱清言推理模式,在117分试卷的测试中得分为78分。
实际上,该模型在多道题目的推理过程中都找到了正确答案,但是往往会在最后一步出现自我怀疑导致逻辑崩溃,陷入循环,最终功亏一篑,白白丢了很多分。

智谱清言推理模式解答过程截图
排在最末尾的是Kimi k1.5,该模型在最后两道压轴大题上栽了大跟头,损失了大量的分数。
综合所有测试情况来看,在处理有固定步骤和严密逻辑的数学问题上,AI推理大模型已经具备很强的能力。但在涉及抽象和创新思维的题目上,目前的大模型还存在一定的局限性。
记者|岳楚鹏 高涵
编辑|金冥羽 兰素英 盖源源
校对|卢祥勇
封面图片来源:视觉中国
|每日经济新闻 nbdnews 原创文章|
未经许可禁止转载、摘编、复制及镜像等使用

1本文为《每日经济新闻》原创作品。
2 未经《每日经济新闻》授权,不得以任何方式加以使用,包括但不限于转载、摘编、复制或建立镜像等,违者必究。










