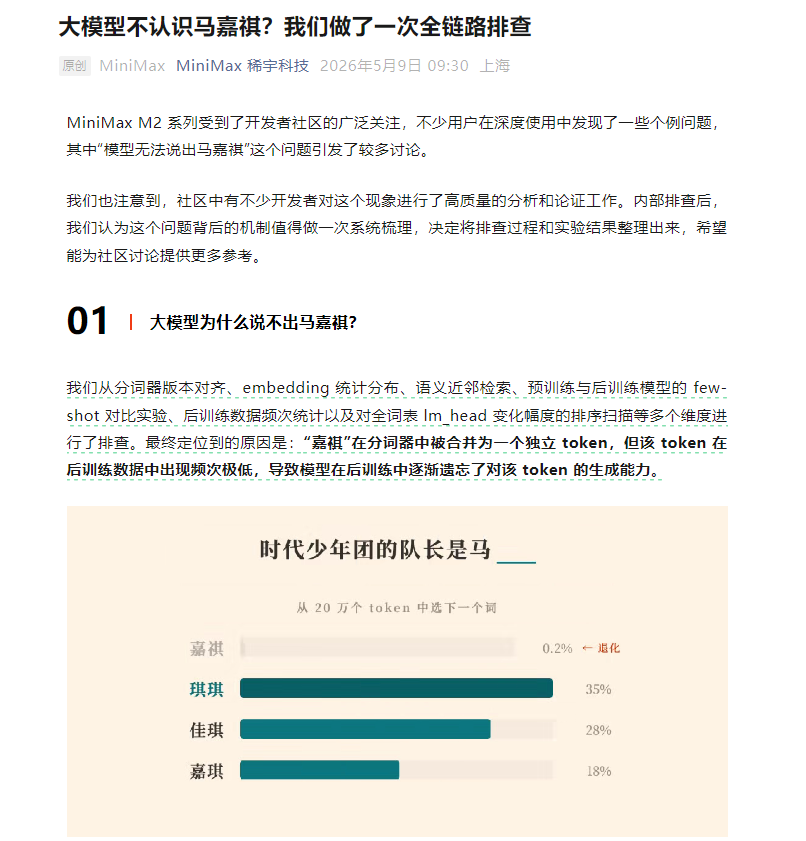
每经AI快讯,5月9日,MiniMax官微发长文回应M2系列模型无法说出马嘉祺一事,提供了对“嘉祺识别”问题的完整排查过程和技术思考。MiniMax表示,其从分词器版本对齐、embedding统计分布、语义近邻检索、预训练与后训练模型的few-shot对比实验、后训练数据频次统计以及对全词表lm_head变化幅度的排序扫描等多个维度进行了排查。最终定位到的原因是:“嘉祺”在分词器中被合并为一个独立token,但该token在后训练数据中出现频次极低,导致模型在后训练中逐渐遗忘了对该token的生成能力。