每经记者|宋欣悦 每经编辑|金冥羽 高涵 向江林
记者|宋欣悦
编辑|金冥羽 高涵 向江林 校对|张锦河
大模型正在从“聊天”进入“干活”的阶段。
真正让开发者和企业用户焦虑的,也不再只是一次问答多少钱,而是 Agent 在长上下文、多轮推理、代码调用和自动化工作流中持续燃烧的 Token 成本。
就在这一节点,DeepSeek 连续两天出手降价。
4月25日晚,DeepSeek宣布对V4-Pro模型API开启限时2.5折价格优惠。26日晚,DeepSeek又宣布DeepSeek全系列API服务,输入缓存命中的价格降至原有价格的1/10。其中,Pro模型在2026年5月5日前叠加2.5折限时优惠。最新调价后,DeepSeek-V4-Flash每百万tokens输入缓存命中价格为0.02元,DeepSeek-V4-Pro为0.025元。
《每日经济新闻》记者(以下简称每经记者)注意到,在OpenRouter上,DeepSeek新模型4月24日上线后调用量已有明显增长。数据显示,4月25日,DeepSeek V4-Pro的调用量为136亿Token,较前一日(4月24日)增长近四倍。
上海财经大学特聘教授胡延平在接受每经记者采访时表示,DeepSeek此举意在延揽更多用户,尤其是企业用户、开发者和各类Agent用户。近几个月国际国内主要模型服务的资费都有较大幅度上涨,DeepSeek 在资费方面再次压低行业价格预期。

4月24日,DeepSeek-V4预览版正式发布并同步开源,号称在Agent能力、世界知识与推理性能三大维度达到国内及开源领域领先水平。
就在模型发布次日(25日晚),DeepSeek宣布DeepSeek-V4-Pro模型API限时2.5折优惠,优惠期截至2026年5月5日。
26日晚,DeepSeek又宣布DeepSeek全系列API服务,输入缓存命中的价格降至原有价格的1/10。Pro模型则在2026年5月5日前叠加2.5折限时优惠。
要知道,在本次连续两日降价之前,DeepSeek-V4的价格本就极具“杀伤力”。同样处理百万Token的输入与输出,GPT-5.5和Claude Opus 4.7的合计成本分别是35美元和30美元。而DeepSeek-V4-Pro仅需5.27美元。如果输入命中缓存,输入价格进一步降至每百万Token 0.145美元,合计成本降至3.66美元。
也就是说,在标准定价下,DeepSeek-V4-Pro的成本大约是GPT-5.5的七分之一、Claude Opus 4.7 的六分之一。如果缓存命中,则大约是GPT-5.5的十分之一、Claude Opus 4.7的八分之一。
而DeepSeek-V4-Flash的输入价格每百万Token仅0.145美元,输出价格0.293美元,合计0.439美元。缓存命中后进一步降至0.322美元。
而现在,降价叠加限时优惠,DeepSeek-V4-Pro输入缓存命中的价格已降低至0.025元/百万Token,为原价的四十分之一。
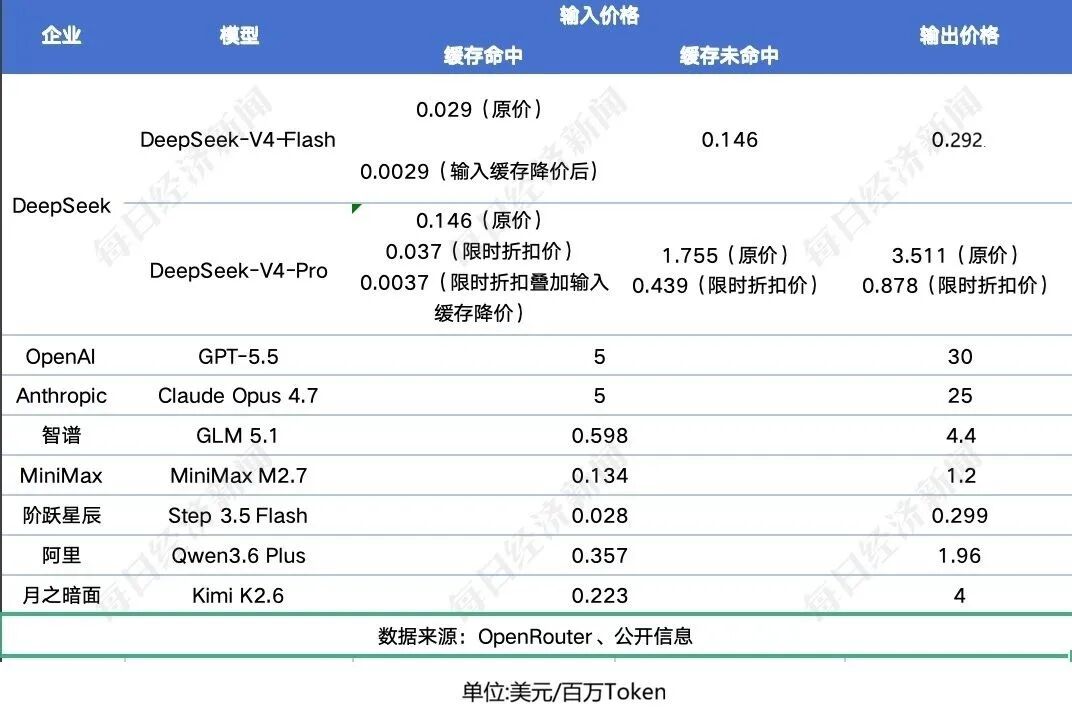
通过上表可以看到,从公开API单价看,DeepSeek-V4系列已进入全球主流高性能模型中的最低价格带。尤其是在输入缓存命中场景下,V4-Pro限时价降至0.0037美元/百万Token,V4-Flash更低至0.0029美元/百万Token,显著低于GPT-5.5、Claude Opus 4.7、Gemini 2.5 Pro等一线闭源模型。不过,若按完整任务成本计算,模型输出Token数、推理长度和任务类型仍会影响最终账单。
DeepSeek这次真正打穿的,不是“所有模型的绝对最低价”,而是“高性能Agent模型的价格锚”。
对此,上海财经大学特聘教授胡延平在接受每经记者采访时指出,DeepSeek此举意在延揽更多用户,尤其是企业用户、开发者和各类Agent用户。
“Agent的Token消耗比较高,V4在模型达到一线水准的情况下,资费显著低于其他国产模型,对用户来说有很大吸引力。”胡延平表示,“近几个月,国际国内主要模型服务资费都有较大幅度上涨,DeepSeek则在资费方面再次击穿行业成本线。”
DeepSeek-V4分为Pro与Flash两个版本,均支持百万(1M)Token超长上下文。
Artificial Analysis对DeepSeek-V4进行了推理能力专项测评。结果显示,V4-Pro在人工分析智能指数中斩获52分,相较V3.2版本的42分实现10分跃升,成为仅次于Kimi K2.6的全球第二大开源推理模型。
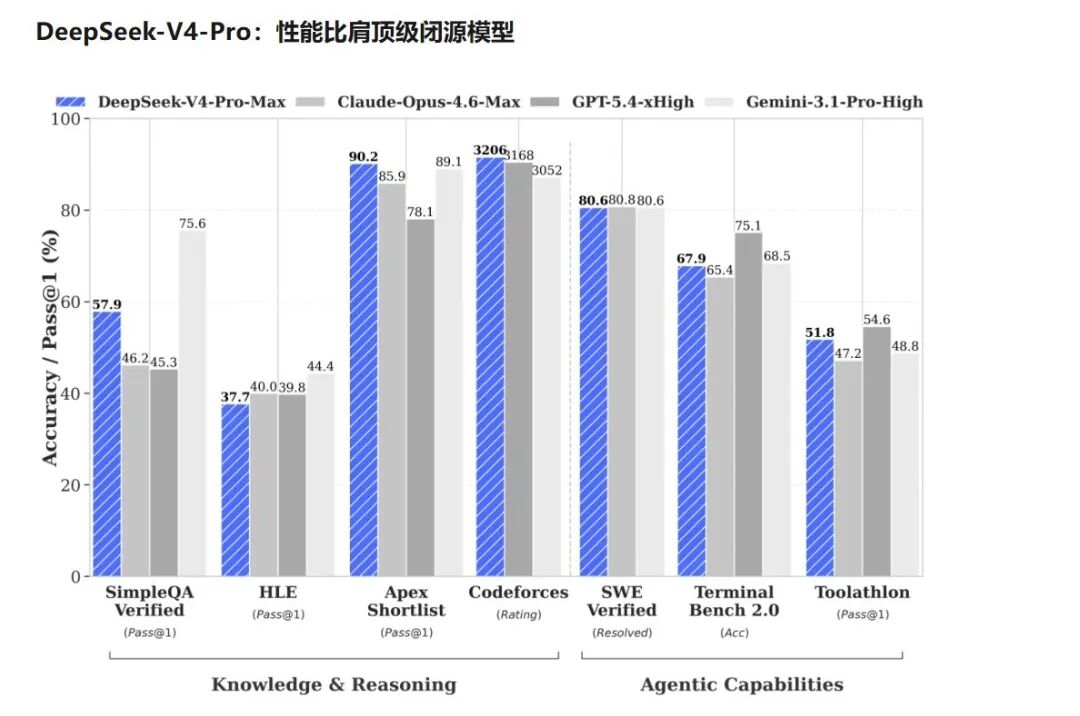 图片来源:DeepSeek微信公众号
图片来源:DeepSeek微信公众号
V4-Flash得分47分,性能弱于V4-Pro,但显著超越DeepSeek-V3.2,综合智能水平对标Claude Sonnet 4.6(全力版),介于顶尖闭源模型与主流中端模型之间。
每经记者注意到,在全球最大AI模型应用程序编程接口聚合平台OpenRouter上,DeepSeek新模型上线后调用量已有明显增长。
数据显示,4月25日,DeepSeek-V4-Flash的调用量为502亿Token,较前一日增长85.9%;DeepSeek-V4-Pro的调用量为136亿Token,较前一日增长近四倍。
不过,这场热度能否持续,仍有待观察。截至发稿,DeepSeek两款新模型并未登上4月20日至26日当周的OpenRouter全球AI大模型周调用量榜单和4月26日的OpenClaw日调用榜。
在DeepSeek首次官宣降价的次日(4月26日),DeepSeek-V4-Flash的调用量为814亿Token,较前日环比增长62.2%。DeepSeek-V4-Pro的调用量为96亿Token,不及前日。
但DeepSeek的猛烈攻势,无疑给其他模型厂商带来了压力。
胡延平分析称:“DeepSeek的超低Token资费会在一定程度上压低部分高性能模型的价格预期,对Kimi K2.6、GLM-5.1、Qwen系列、MiniMax等国产模型的价格预期形成压力。”
那么,这是否意味着大模型Token价格的拐点已至?胡延平认为,如果后续国产推理算力能进一步大规模部署,在Agent应用不断拉高消耗量的情况下,有望平抑持续上涨的Token价格。但他同时也强调,此举对GPT-5.5、Claude 4.7 Opus等顶尖模型的影响可能相对有限。
但无论如何,DeepSeek-V4这条“鲶鱼”的闯入,已经开始搅动大模型市场。对于广大开发者和用户而言,一个选择更多、成本更低的新时代,或许正加速到来。
(免责声明:本文内容与数据仅供参考,不构成投资建议,使用前请核实。据此操作,风险自担。)
|每日经济新闻 nbdnews 原创文章|
未经许可禁止转载、摘编、复制及镜像等使用

1本文为《每日经济新闻》原创作品。
2 未经《每日经济新闻》授权,不得以任何方式加以使用,包括但不限于转载、摘编、复制或建立镜像等,违者必究。










