◎OpenAI对B端市场的布局一年前就开始了。
每经记者|蔡鼎 每经编辑|高涵
美东时间8月20日(周二),OpenAI宣布将面向企业客户推出“个性化定制服务”,允许使用各自的公司数据来“微调”(Fine-tuning)其目前最强大的AI模型GPT-4o。
有分析称,对于OpenAI当前的旗舰模型来说,微调是全新的功能,GPT-4o及其前身GPT-4此前均未提供过微调功能。最新举动说明各大AI模型研发公司针对企业客户的竞争加剧。
从去年8月份推出面向大型企业的ChatGPT企业版(ChatGPT Enterprise),到11月份低调推出起步价为200万美元企业定制版GPT-4,再到如今面向企业客户推出“个性化定制服务”,OpenAI不断在B端客户方向上布局。
业内机构对OpenAI的营收推算显示,企业端的用户已经为OpenAI贡献了近30%的收入。随着OpenAI对B端市场布局的进一步完善,这个占比或将进一步上升。
不过,值得注意的是,OpenAI周二表示,为了微调模型,客户必须将特定数据集上传到OpenAI的服务器,这意味着与这些服务的所有交互数据都面临着被暴露的风险。
其实,OpenAI对B端市场的布局一年前就开始了。
2023年8月,OpenAI推出了面向大型企业的ChatGPT企业版(ChatGPT Enterprise),称这是迄今为止最强大的ChatGPT版本。据OpenAI介绍,除了和一般ChatGPT一样执行编写电邮、起草文件和调试电脑代码等任务外,当时的企业版还可提供企业级的安全和隐私,以及高级数据分析功能。外媒分析称,ChatGPT Enterprise的推出意味着,OpenAI将全面开拓企业用户战场,与其最大金主和合作伙伴微软直接竞争。
三个月后的2023年11月,OpenAI又低调推出了企业定制版GPT-4。根据OpenAI的说法,它会选择一些特定客户,基于这些客户自己的私有数据,构建定制化的GPT-4模型,生成针对每个客户业务的自定义结果。
OpenAI当时表示,推出每个客户的定制流程需要花费几个月的时间,起步价为200万美元。200万美元的价格虽然高昂,但值得注意的是,OpenAI提供的GPT-4定制服务水平可能远远高于大多数竞争对手。全新定制化服务,可以使OpenAI直接与Databricks、OctoML等公司竞争,后者也提供了使用客户自有数据训练开源模型的定制服务。
而为什么OpenAI早在一年前就“杀入”B端市场,从上个月机构对OpenAI营收的拆解可以看出,企业端用户贡献的营收已经超过了20%。
人工智能调研机构FutureSearch7月份得出的数据结果显示,ChatGPT Plus订阅是OpenAI最大的收入来源,贡献了总收入的55%,约19亿美元。在B端市场,OpenAI针对大型企业客户的ChatGPT Enterprise为OpenAI贡献了21%的收入,约7.44亿美元。据估计,目前有120万个企业用户在使用ChatGPT Enterprise,每个账户每月收费50美元。
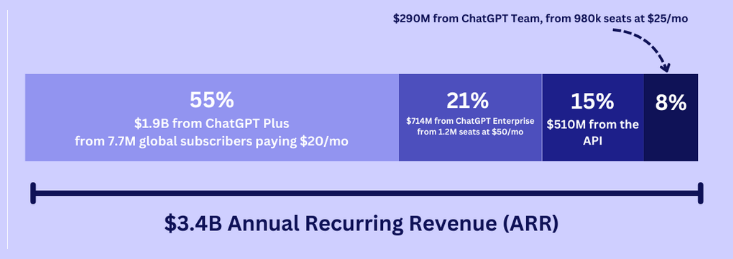
图片来源:FutureSearch
面向中小企业和团队用户的ChatGPT Team为OpenAI贡献了8%的收入,约2.9亿美元。ChatGPT Team每个账户每月收费25美元,估计有98万个用户。最后,API接口服务为公司贡献了15%的收入,约5.1亿美元。也就是说,OpenAI的营收中已经有近30%(约10.34亿美元)来自企业客户。随着OpenAI对B端市场布局的进一步深入,这个占比或还将进一步提升。
《每日经济新闻》记者注意到,在去年11月“悄悄”推出企业定制版GPT-4时,就有声音担心企业数据安全的问题——在当时的定制服务框架下,OpenAI会利用客户自有的大量内部文档数据,定制训练出一个功能更强、更适合公司业务需要的GPT-4版本。而在本周二宣布将面向企业客户推出“个性化定制服务”时,网络/数据安全的问题再次受到外界的广泛关注。
OpenAI周二表示,为了微调模型,客户必须将特定数据集上传到OpenAI的服务器,OpenAI在官网公告中强调了“数据隐私与安全”。公司称,“经过微调的模型完全由您控制,您完全拥有您的业务数据,包括所有输入和输出。这确保您的数据永远不会被共享或用于训练其他模型。我们还为经过微调的模型实施了分层安全缓解措施,以确保它们不会被滥用。例如,我们持续对经过微调的模型进行自动安全评估,并监控使用情况,以确保应用程序遵守我们的使用政策。”
尽管如此,但外界对OpenAI使用企业内部数据训练ChatGPT,以及数据泄露等方面的担忧从未停止。其实,当企业使用OpenAI的ChatGPT时,大模型提供的和/或生成的对话数据都可能被用来训练和微调OpenAI的模型。这意味着与这些服务的所有交互数据都面临着被暴露的风险。
2023年3月底,在ChatGPT被接连发现意外泄露用户聊天记录后,意大利数据保护局(Garante per la Protezione dei Dati Personali)宣布将暂时禁用ChatGPT并对该工具涉嫌违反隐私规则展开调查。今年4月,加拿大开始对OpenAI“未经同意收集、使用和披露个人信息”的投诉进行调查。
去年年底,Open AI和微软还被《纽约时报》提起诉讼,指控其未经许可使用《纽约时报》数百万篇文章训练聊天机器人。《纽约时报》表示,此类侵权行为降低了读者访问其网站的感知需求,减少了流量,并可能削减广告和订阅收入,从而威胁到高质量的新闻报道。Open AI和微软反驳称,使用受版权保护的作品来训练人工智能产品是“合理使用”,这是一种管理未经许可使用受版权保护材料的法律原则。
不过,需要指出的是,这并不是OpenAI或ChatGPT的个例,其暴露出的隐私泄露、存储敏感信息、未授权访问等数据安全问题是大模型产品落地应用后可能普遍面临的问题。

1本文为《每日经济新闻》原创作品。
2 未经《每日经济新闻》授权,不得以任何方式加以使用,包括但不限于转载、摘编、复制或建立镜像等,违者必究。











