每经记者|蔡鼎 每经编辑|程鹏 兰素英
对于专注于构建专业人工智能(AI)模型的开发人员来说,他们面临的长期挑战是获取高质量的训练数据。较小的专家模型(参数规模在10亿~100亿)通常利用“蒸馏技术”,需要利用较大模型的输出来增强其训练数据集,然而,使用来自OpenAI等闭源巨头的此类数据受到严格限制,因此大大限制了商业应用。
而就在北京时间7月23日(周二)晚间,全球AI领域的开发人员期待已久的开源大模型“ChatGPT时刻”终于到来——Meta发布最新AI模型Llama 3.1,其中参数规模最大的是Llama 3.1-405B版本。
扎克伯格将Llama 3.1称为“艺术的起点”,将对标OpenAI和谷歌公司的大模型。测试数据显示,Meta Llama 3.1-405B在GSM8K等多项AI基准测试中超越了当下最先进的闭源模型OpenAI GPT-4o。这意味着,开源模型首次击败目前最先进的闭源大模型。
而且,Llama 3.1-405B的推出意味着开发人员可以自由使用其“蒸馏”输出来训练小众模型,从而大大加快专业领域的创新和部署周期。

2024年4月,Meta推出开源大型语言模型Llama 3。其中,Llama 3-8B和Llama 3-70B为同等规模的大模型树立了新的基准,然而,在短短三个月内,随着AI的功能迭代,其他大模型很快将其超越。
在你追我赶的竞争环境下,Meta最新发布了AI模型Llama 3.1,一共有三款,分别是Llama 3.1-8B、Llama 3.1-70B和Llama 3.1-405B。其中,前两个是4月发布的Llama 3-8B和Llama 3-70B模型的更新版本。而Llama 3.1-405B版本拥有4050亿个参数,是Meta迄今为止最大的开源模型之一。
而在发布当天的凌晨(北京时间),“美国贴吧”reddit的LocalLLaMA子论坛泄露了即将推出的三款模型的早期基准测试结果。
泄露的数据表明,Meta Llama 3.1-405B在几个关键的AI基准测试中超越了OpenAI的GPT-4o。这对开源AI社区来说是一个重要的里程碑:开源模型首次击败目前最先进的闭源大模型。
而Meta团队研究科学家Aston Zhang在X上发布的内容,也印证了被泄露的测试数据。

图片来源:X
具体来看,Meta Llama 3.1-405B 在IFEval、GSM8K、ARC Challenge和Nexus等多项测试中均优于GPT-4o。但是,它在多项MMLU测试和GPQA测试等方面却落后于 GPT-4o。另外,Llama 3.1的上下文窗口(context window)涵盖128000个标记,比以前的Llama模型更大,大约相当于一本50页书的长度。
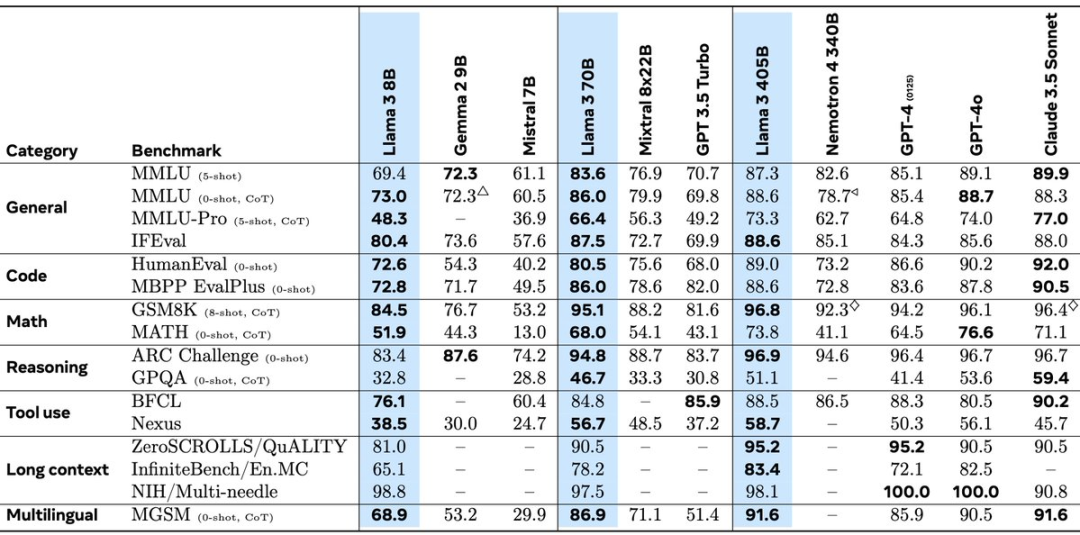
图片来源:X
但需要指出的是,值得注意的是,这些基准反映的是Llama 3.1基本模型的性能。这些模型的真正潜力可以通过指令调整来实现,而指令调整过程可以显著提高这些模型的能力。即将推出的Llama 3.1模型的指令调整版本预计会产生更好的结果。
尽管OpenAI即将推出的 GPT-5预计将具备先进的推理能力,可能会挑战Llama 3.1在大模型领域的潜在领导地位,但Llama 3.1对标GPT-4o的强劲表现仍然彰显了开源AI开发的力量和潜力。
要知道,对于专注于构建专业AI模型的开发人员来说,他们面临的长期挑战是获取高质量的训练数据。较小的专家模型(参数规模在10亿~100亿)通常利用“蒸馏技术”,需要利用较大模型的输出来增强其训练数据集,然而,使用来自OpenAI等闭源巨头的此类数据受到严格限制,因此大大限制了商业应用。
而Llama 3.1-405B的推出意味着开发人员可以自由使用其“蒸馏”输出来训练小众模型,从而大大加快专业领域的创新和部署周期。预计高性能、经过微调的模型的开发将激增,这些模型既强大又符合开源道德规范。
宾夕法尼亚大学沃顿商学院副教授伊桑·莫利克(Ethan Mollick)写道:“如果这些数据属实,那么可以说顶级AI模型将在本周开始免费向所有人开放。全球各地都可以使用相同的AI功能。这会很有趣。”
Llama 3.1-405B的开源,也证明开源模型与闭源模型的差距再次缩小了。
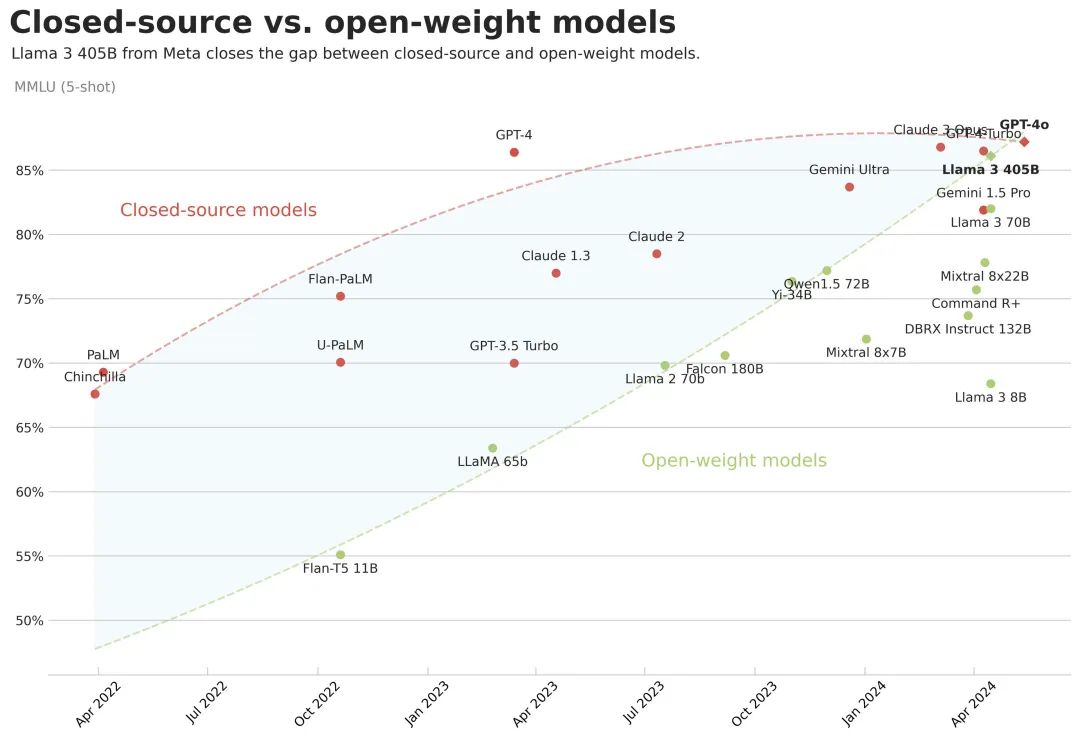
图片来源:X
《每日经济新闻》记者还注意到,除了广受期待的Llama 3.1-405B外,外媒报道称,Llama 4已于6月开始训练,训练数据包括社交平台Facebook和Instagram用户的公开帖子。而在开始之前,Mate已经向数据隐私监管最严格的欧盟地区用户发送超过20亿条通知,提供了不同意把自己数据用于大模型训练的选项。
据悉,Llama 4将包含文本、图像、视频与音频模态,Meta计划将新模型应用在手机以及智能眼镜中。
记者|蔡鼎
编辑|程鹏 兰素英 杜恒峰
校对|陈柯名
 |每日经济新闻 nbdnews 原创文章|
|每日经济新闻 nbdnews 原创文章|
未经许可禁止转载、摘编、复制及镜像等使用

1本文为《每日经济新闻》原创作品。
2 未经《每日经济新闻》授权,不得以任何方式加以使用,包括但不限于转载、摘编、复制或建立镜像等,违者必究。










