26日,360集团创始人、董事长@周鸿祎在微博发布视频称,他认为“OpenAI对中国地区停止服务只能加速中国自己大模型产业的发展,未必是一个坏事。”他解释道:“OpenAI的API无法调用,这逼着国内应用只能选择国产大模型,而国产大模型与GPT的差距已经逐渐缩小了。”
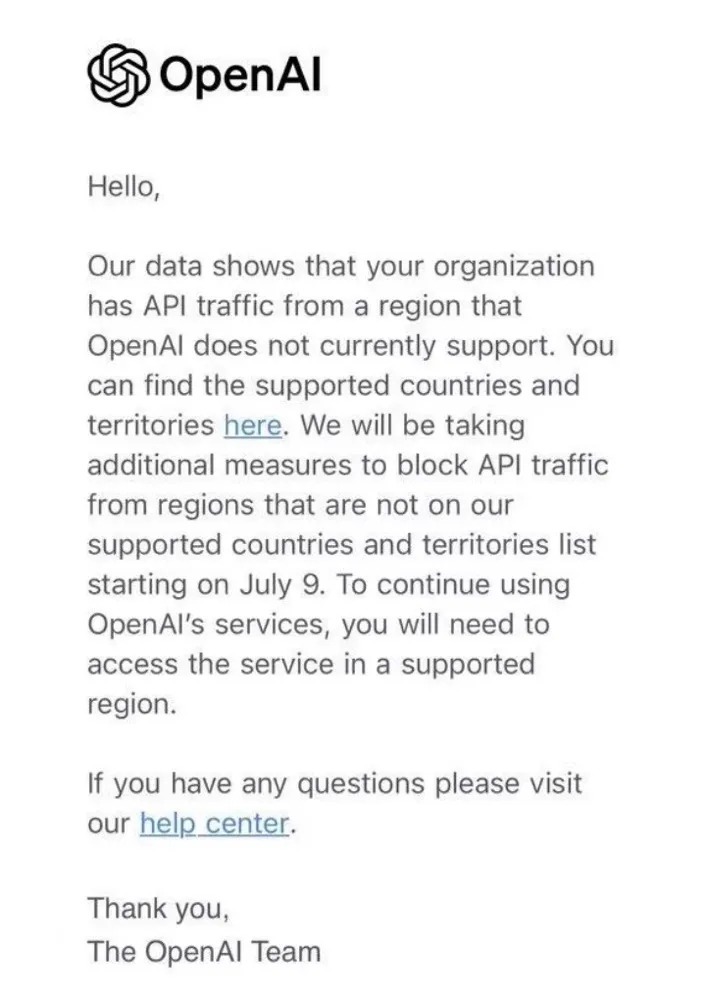
消息面上,6月25日,OpenAI向中国用户发布邮件称,自7月9日起阻止来自非支持国家和地区的API流量。受影响组织若希望继续使用OpenAI的服务,必须在其支持的国家或地区内访问。目前,OpenAI的API向161个国家和地区开放,由于中国未在其中,这意味着OpenAI将终止对中国提供API服务。
值得一提的是,25日,每日经济新闻大模型评测报告(第1期)发布。《每日经济新闻大模型评测报告》(第一期)显示,国产大模型正在全面赶超海外大模型,零一万物Yi-Large成为最大“黑马”,在“财经新闻标题创作”“微博新闻写作”“文章差错校对”“财务数据计算与分析”四大应用场景的总分排名第一。幻方求索DeepSeek-V2、百川智能Baichuan4则在“财务数据计算与分析”场景显示出强大的数据计算和分析能力。而一直备受各界推崇的GPT 4.0在本次评测中表现不佳,甚至在“财经新闻标题创作”场景中排名垫底。
OpenAI对中国API“停服”!
据媒体报道,25日,OpenAI宣布终止对包括中国大陆在内的地区提供API服务。25日凌晨,部分开发者收到了来自OpenAI官方的邮件。
邮件显示:“我们的数据显示,贵组织的APl流量来自OpenAl目前不支持的地区。您可以在此处找到受支持的国家和地区。我们将从7月9日开始采取额外措施,阻止来自不在我们支持的国家和地区列表中的地区的APl流量。要继续使用OpenAl的服务,您需要在受支持的地区访问服务。”
据悉,目前OpenAI的API向161个国家和地区开放,但中国大陆未包含在其中。这也意味着,OpenAI宣布终止对中国大陆提供API服务。
阿里云百炼第一时间宣布,将为OpenAI API用户提供最具性价比的中国大模型替代方案,并为中国开发者提供2200万免费tokens和专属迁移服务。根据斯坦福最新公布的大模型测评榜单HELM MMLU,Qwen2-72B得分为0.824,与GPT-4并列全球第四。通义千问GPT4级主力模型Qwen-plus在阿里云百炼上的调用价格为0.004元/千tokens,仅为GPT-4的50分之一。
6月25日,智谱推出OpenAI API用户特别搬家计划,帮助用户切换至国产大模型。具体来看,智谱为开发者提供:1.5亿Token(5000万GLM-4+1亿GLM-4-Air);从OpenAI到GLM的系列迁移培训。对于高用量客户,智谱提供与OpenAI使用规模对等的Token赠送计划(不设上限),以及与OpenAI对等的并发规模等。
6月25日,百度智能云千帆推出大模型普惠计划,即日起为新注册企业用户提供0元调用、0元训练、0元迁移等服务。
其中,文心旗舰模型首次免费,赠送ERNIE3.5旗舰模型5000万Tokens包,主力模型ERNIE Speed/ERNIE Lite和轻量模型ERNIE Tiny持续免费;针对OpenAI迁移用户额外赠送与OpenAI使用规模对等的ERNIE3.5旗舰模型Tokens包。以上优惠活动均在2024年7月25日24点前适用。
国产大模型正全面赶超
近期,由30余位每日经济新闻优秀记者、编辑和子公司每经科技工程师组建的“每日经济新闻大模型评测小组”,对市场上主流大模型在财经新闻工作场景中的表现与能力进行了历时2个月深入评测,并于6月25日发布了《每日经济新闻大模型评测报告》(第一期)。
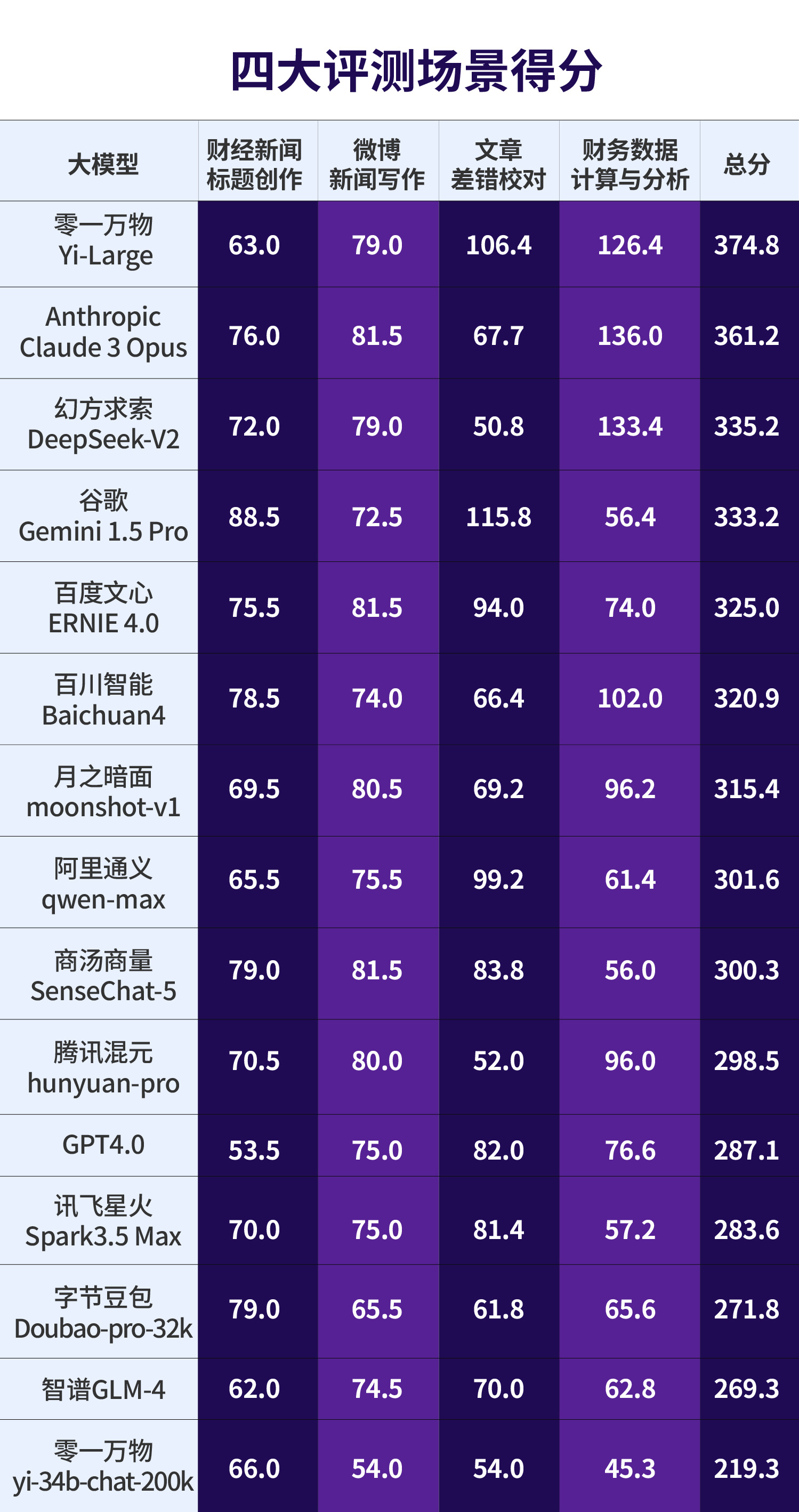
《每日经济新闻大模型评测报告》(第一期)显示,国产大模型正在全面赶超海外大模型,零一万物Yi-Large成为最大“黑马”,在“财经新闻标题创作”“微博新闻写作”“文章差错校对”“财务数据计算与分析”四大应用场景的总分排名第一。幻方求索DeepSeek-V2、百川智能Baichuan4则在“财务数据计算与分析”场景显示出强大的数据计算和分析能力。而一直备受各界推崇的GPT 4.0在本次评测中表现不佳,甚至在“财经新闻标题创作”场景中排名垫底。
经过评测,《每日经济新闻大模型评测报告》(第一期)得出以下结论。
结论一:国产大模型正全面赶超
国产大模型正逐渐展现出其竞争力。与国外大模型相比,它们在多个任务上的表现已经显示出赶超之势。
国产大模型在多个测试场景中排名靠前。商汤商量SenseChat-5三次占据前五席位,两次击败谷歌Gemini 1.5 Pro。在国外模型中,Anthropic Claude 3 Opus同样在三个测评场景中排名前五,谷歌Gemini 1.5 Pro在“财经新闻标题创作”和“文章差错校对”两个场景中排名第一。令人意外的是,一直备受各界推崇的GPT 4.0却在本次评测中整体表现不佳,在每个场景中都未能斩获前五名,甚至在“财经新闻标题创作”中排名垫底。
“财经新闻标题创作”场景中,商汤商量SenseChat-5、字节豆包Doubao-pro-32k和百度ERNIE 4.0等,在信息提炼准确和重要新闻点突出方面与谷歌的Gemini 1.5 Pro不相上下。
“微博新闻写作”场景中,百度文心ERNIE 4.0、商汤SenseChat-5等模型的总分与国外模型Anthropic Claude 3 Opus并列第一。
“文章差错校对”场景中,零一万物Yi-Large是唯一一款得分超过100分的国产大模型。国产大模型比国外大模型更能理解汉语句式和表达规范。但在查找并修改错别字、标点使用不当、数字和量词错误、事实和信息错误等要求更精准的任务方面,还有提升空间。
“财务数据计算和分析”场景中,Anthropic Claude 3 Opus总分虽领先,但对幻方求索DeepSeek-V2和零一万物Yi-Large的优势并不大。尤其是幻方求索DeepSeek-V2成为此场景评测中一匹“黑马”,其“财务数据分析”能力突出。
结论二:大模型各有专长
不同模型在特定场景、特定维度、特定指标上的表现差异显著。体现了它们在各自领域的专长。
例如,谷歌Gemini 1.5 Pro在“财经新闻标题创作”和“文章差错校对”两大场景中排名第一。在“微博新闻写作”场景中,该模型整体排名靠后。
Anthropic Claude 3 Opus、幻方求索DeepSeek-V2、百川智能Baichuan4则显示出了强大的数据计算能力。
结论三:在跨语言环境下差异明显
以“微博新闻写作”场景为例,百度文心ERNIE 4.0、商汤商量SenseChat-5与Anthropic Claude 3 Opus并列第一。这反映了国产大模型在微博这一国内社交媒体场景下的卓越表现。国产大模型更能够准确把握微博用户的内容偏好和交流方式,生成符合平台特性和用户期待的微博文案。
相比之下,谷歌Gemini 1.5 Pro在微博写作的运营维度上得分为0,可能源于其对微博平台特性和用户行为的不熟悉。
在中文语境之下,GPT 4.0在全部4个场景中的排名均不理想。这一现象突显了大模型在跨语言和文化环境中的适应性问题,也表明了国产大模型在本土化应用上具有天然优势。
结论四:信息提取能力参差不齐
从文章中准确提取关键信息,是对大模型能力的一项关键挑战。本期评测中“文章差错校对”场景正包含了对这一能力的测试。
谷歌Gemini 1.5 Pro凭借其在错别字、标点使用不当、数字和量词错误、事实和信息错误的查找和纠错方面与其他大模型拉开了差距。
相比之下,零一万物Yi-Large在病句查找和纠错方面则位居首位,本可以挑战谷歌Gemini 1.5 Pro,但在错误查找方面的表现拖了后腿。
大模型信息提取能力的差异可能与模型的训练数据、算法设计以及对语言细微差别的捕捉能力有关。增强大模型的信息提取能力,可以提高其生成结果的准确度,更能让大模型适用于对准确性要求极高的新闻工作。
每日经济新闻综合@周鸿祎










