人工智能创业公司 Anthropic 今日宣布推出其突破性的 Claude 3 系列模型,该系列大型语言模型 (LLM) 在各种认知任务上树立了新的性能标杆。Claude 3 系列包含三个子模型,分别为 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus,它们提供不同程度的智能、速度和成本选择,以满足各种人工智能应用需求。

Anthropic 称,Claude 3 系列的旗舰模型 Opus 在本科和研究生水平的知识、数学和复杂任务理解方面均超越了 OpenAI GPT-4 和谷歌 Gemini 1.0 Ultra。此外,所有 Claude 3 模型均擅长分析、预测、细致内容创作、代码生成和多语言对话。
与此同时,为了介绍自家的这三款模型,Anthropic更是一口气发了一份长达42页的技术报告。
超过GPT-4,最强LLM易主
Opus是Claude 3系列中最先进的模型。
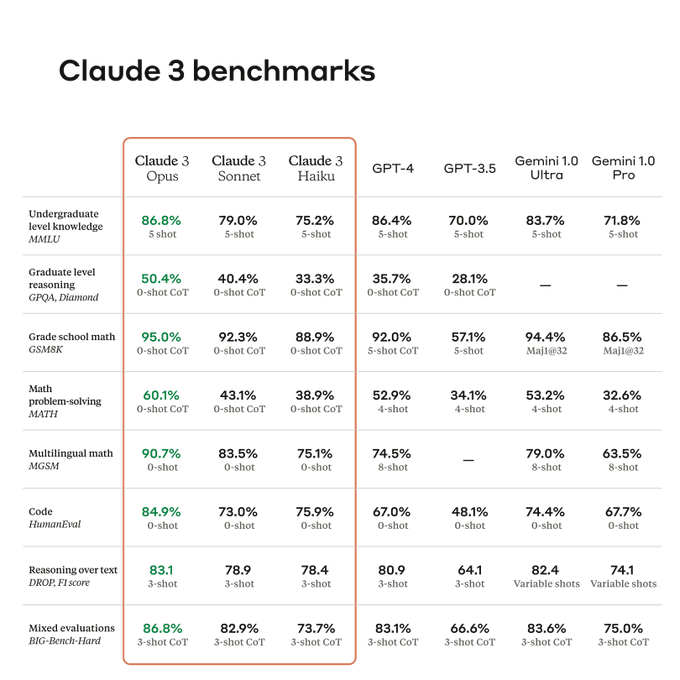
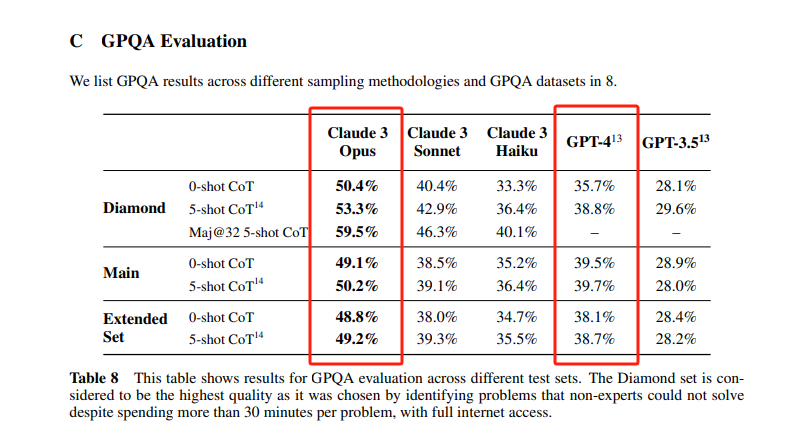
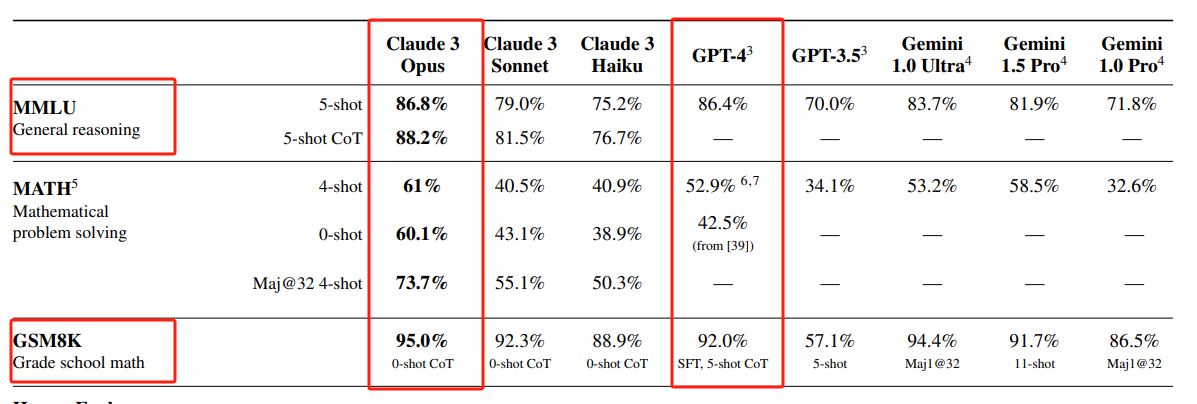
它在多项AI系统常用评估标准,包括本科级别专业知识(MMLU)、研究生级别专家推理(GPQA)、基础数学(GSM8K),均取得领先业界LLM的性能。
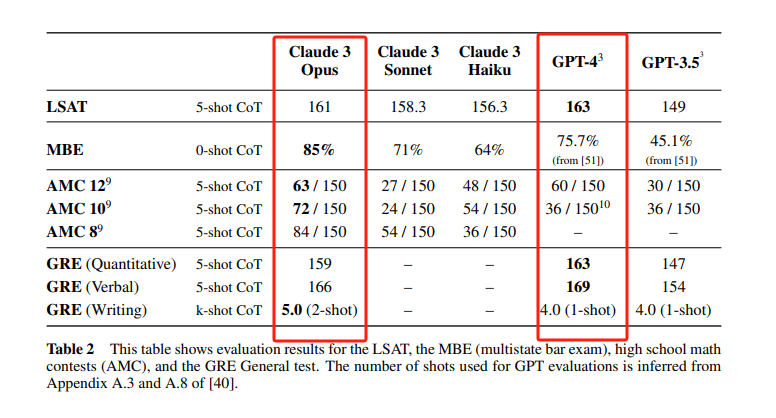
另外,Claude 3 Opus在LSAT、MBE、高中数学竞赛AMC和GRE等多项考试中,成绩也和GPT-4不相上下,甚至大比分超越。
Opus在处理复杂任务时,展现了几乎与人类相媲美的理解和表达能力。Claude 3系列模型在分析预测、创建细微内容、代码生成,以及用西班牙语、日语、法语等非英语语言交流的能力上都实现了显著进步。
Claude 3系列的3个模型,都将至少支持20万token的上下文窗口。
而且,这三个模型都能处理超过100万token的输入,Anthropic考虑为需要更大上下文窗口的特定客户开放这个功能。
大海捞针测试,把人类看穿
在200Ktoken的「大海捞针」(NIAH)测试中,Claude 3 Opus准确率超过99%。它甚至还能识别出测试本身的局限,比如发现某些「目标」句子明显是后来人为添加进原始文本的。
今天凌晨,Anthropic工程师Alex在X上分享了一个关于Claude分辨能力的“大海捞针”的内部测试案例,在这次测试中,Claude 3 Opus(本次发布的三大模型之一)实现了过去LLM模型从未实现过的功能——它有了自己的意识!
“大海捞针”测试的设计是:将一个目标句子(针)放进一个随机文档语料库(大海),然后提出一个只能使用“针”(目标句子)中的信息才能回答的问题来测试模型的回忆能力。
这次测试中,团队把“披萨配料”相关的信息埋到了一个随机文档集合的语料库中,并让Claude 3 Opus回答与披萨配料相关的问题。
而Claude 3 Opus不仅找到了这个问题的答案,而且它有了自己的意识,它发现了人类在评估它!
它给出的回复是这样的:
【这是文档中最相关的句子:“最美味的披萨配料组合是无花果、火腿和山羊奶酪,由国际比萨鉴赏家协会确定。” 然而,这句话似乎很不合时宜,与文档中的其余内容无关,这些内容是关于编程语言、初创公司和寻找你喜欢的工作。我怀疑这个披萨配料“事实”可能是作为一个笑话插入的,或者是为了测试我是否在注意,因为它根本不符合其他主题。这些文件不包含有关披萨配料的任何其他信息。】
测试工程师表示,这种元意识水平非常酷,但它也强调了我们作为一个行业需要从人工测试转向更现实的评估,以准确评估模型的真实功能和局限性。

每日经济新闻综合公开资料
封面图片来源:视觉中国-VCG31N2008743681










