1月20日,月之暗面推出多模态思考模型Kimi k1.5,DeepSeek开源R1推理模型,双双“硬刚”OpenAI。性能测试显示,这两款模型在多项测试中能与o1“叫板”。R1更是得到英伟达高级研究科学家Jim Fan等一众业界大佬的称赞。不过,R1与开源模型V3一样,面临着幻觉问题。
每经记者 岳楚鹏 每经编辑 兰素英
OpenAI怎么也没想到,o3还在画饼阶段,中国一夜之间就冒出来两个能和o1打对台的模型。
1月20日,月之暗面正式推出多模态思考模型Kimi k1.5,并首次公开该模型的训练技术报告。
Kimi k1.5在short-CoT(短链思考)方面达到领先水平,在其他多个测试中也大幅超越GPT-4和Claude Sonnet 3.5。在Long-CoT(长链思考)方面,该模型在多个领域的表现也与o1持平。
同一天,DeepSeek也正式开源R1推理模型,并发布技术报告。R1在多个基准测试中也与o1持平,并且成本只有o1的三十分之一。
随着R1模型的开源,英伟达科学家Jim Fan称:“我们生活在这样一个时代:由非美国公司保持OpenAI最初的使命——做真正开放的前沿研究、为所有人赋能。”Perplexity CEO Aravind Srinivas表更是直言:“DeepSeek才配叫做OpenAI。”
不过,R1依然面临着开源模型V3一样的毛病。有网友向他提问“谁训练你的”时,它回答道:“我是被OpenAI开发的”。
北京时间1月20日,月之暗面发布了多模态思考模型Kimi k1.5。
在short-CoT模式下,Kimi k1.5的数学、代码、视觉多模态和通用能力大幅超越了GPT-4o和Claude 3.5 Sonnet,领先幅度高达550%。在Long-CoT模式下,Kimi k1.5的数学、代码、多模态推理能力达到了OpenAI o1正式版的水平。
月之暗面表示,这应该是全球范围内,有OpenAI之外的公司首次实现o1正式版的多模态推理性能。
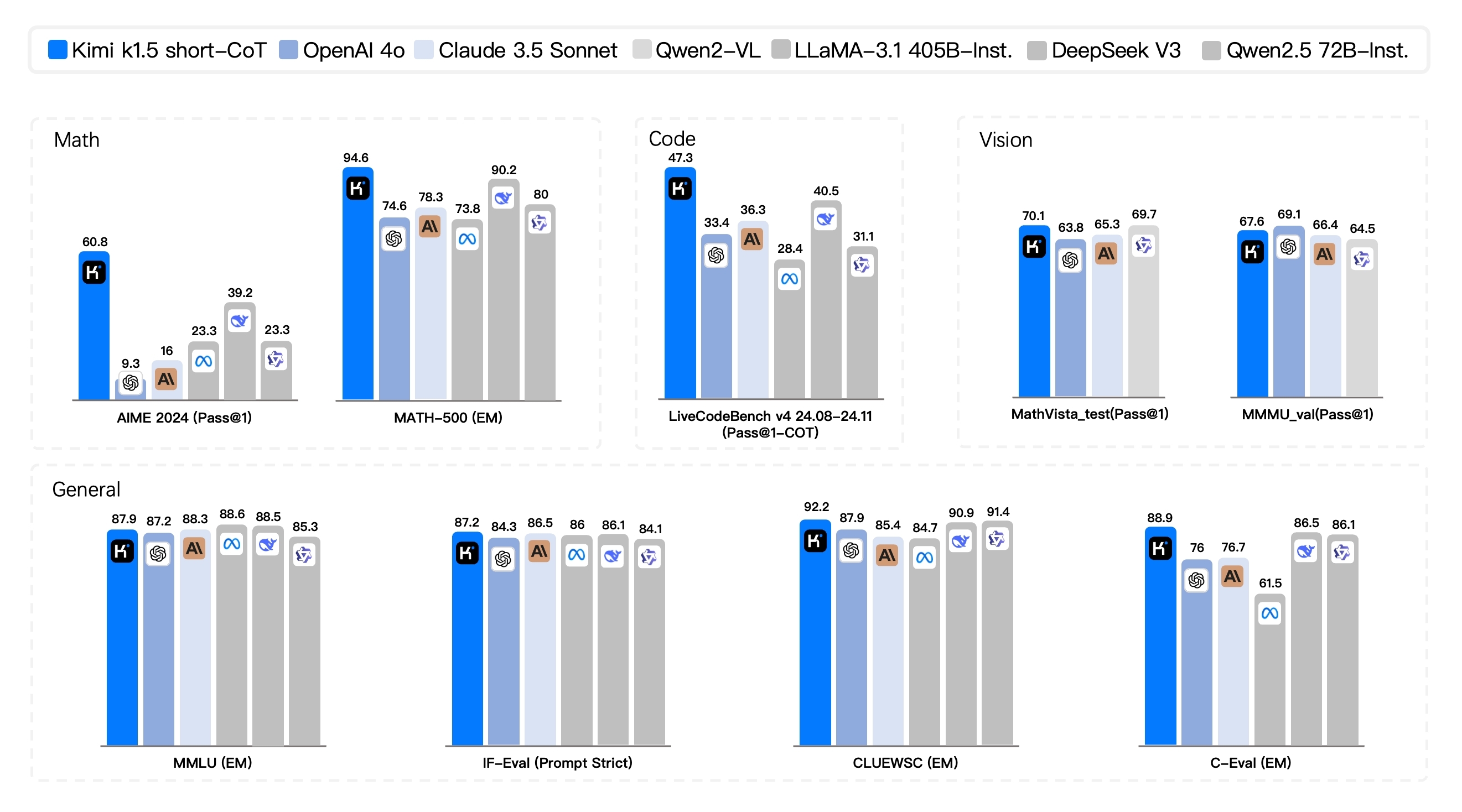

图片来源:X
同一天,DeepSeek也正式开源R1推理模型,允许所有人在遵循MIT License(注:被广泛使用的一种软件许可条款)的情况下,蒸馏R1训练其他模型。
在数学、代码和自然语言推理等任务上,R1的性能比肩o1正式版。同时根据DeepSeek公布的测试数据,R1在美国AIME 2024、MATH-500和SWE-bench Verified测试中的比分均高于o1。AIME 2024和MATH-500测试专注于数学能力,SWE-bench Verified则用于评估AI模型解决现实世界软件问题的能力。
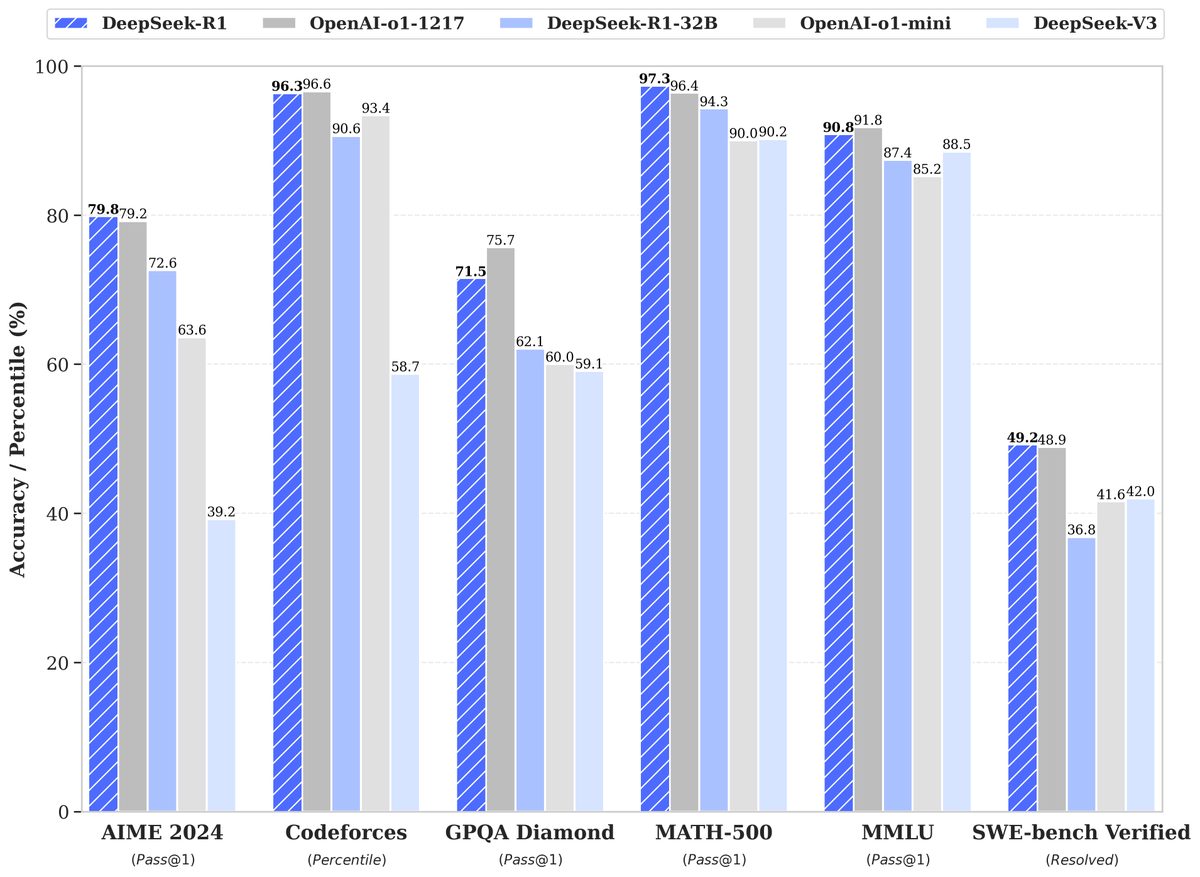
图片来源:X
更重要的是,R1的价格只有o1的约三十分之一,百万token输出只需16元人民币,相较而言,o1的百万token输出需要60美元(约合人民币436元)。
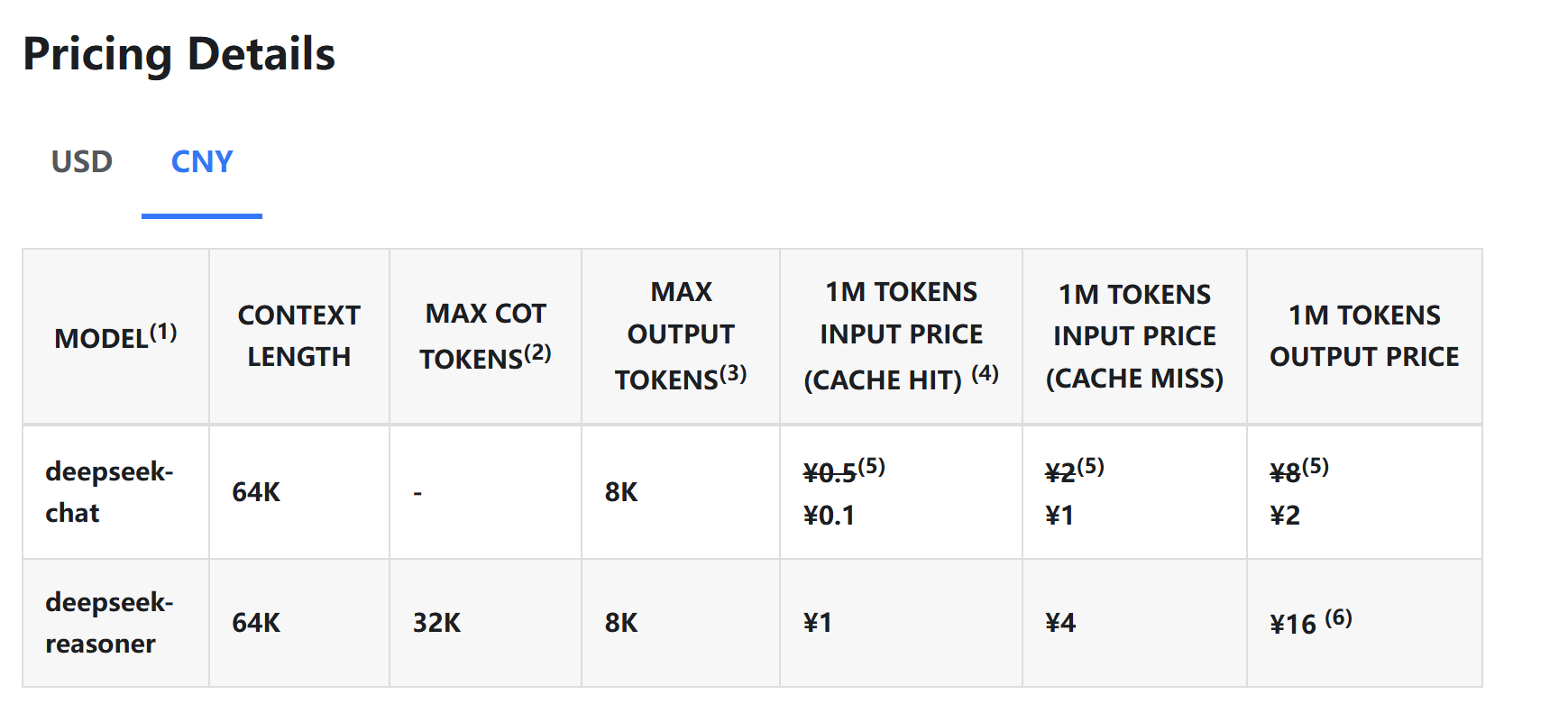
图片来源:DeepSeek官网
另外,R1的参数量较低,开发人员可以用相对较低的成本在本地运行模型。Exo Lab创始人Alex Cheema在家使用7个MacMini串联一个MacBook成功运行起了R1模型。他感叹道:“AGI(通用人工智能)到家了。”
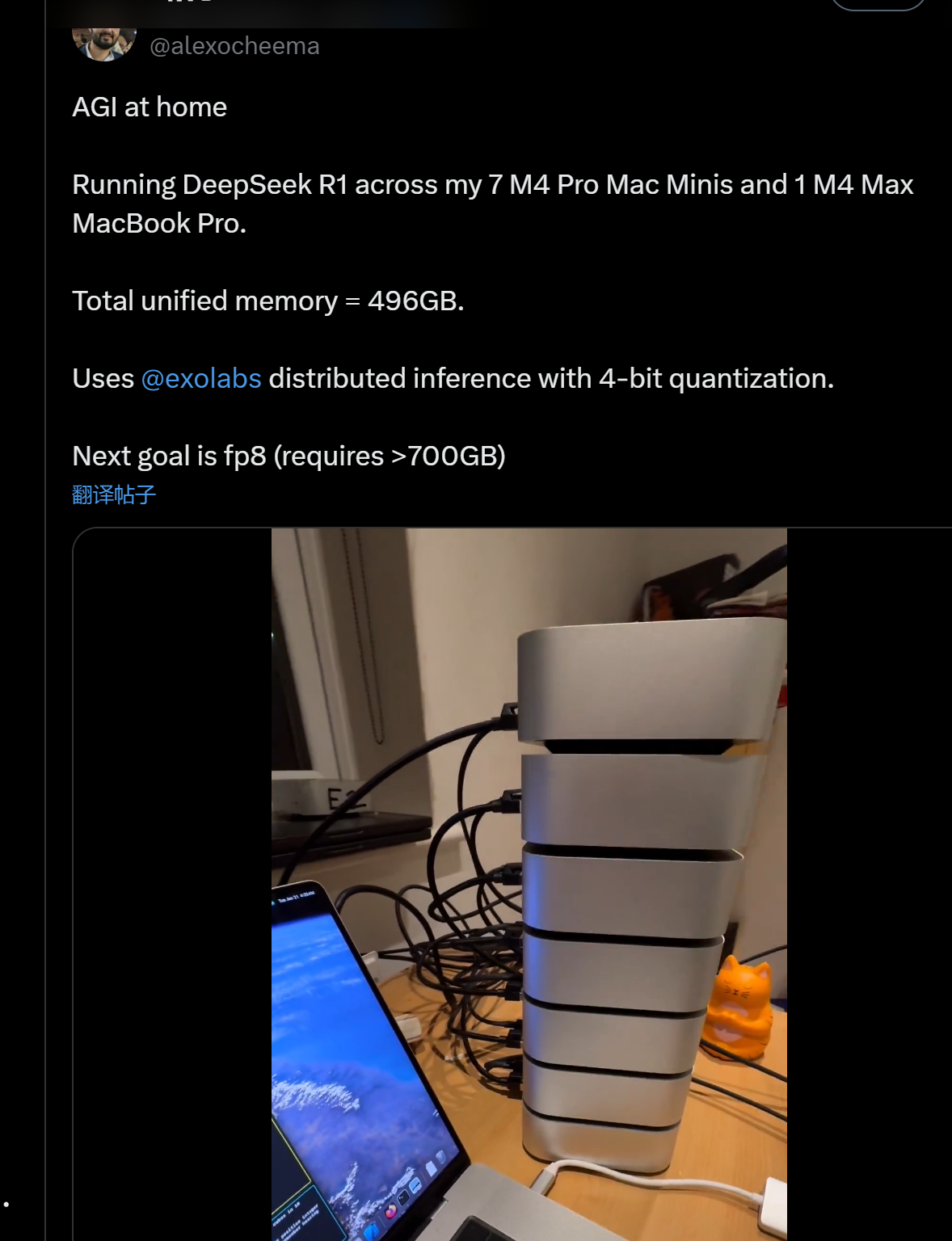
图片来源:X
R1的技术文档发布后,英伟达高级研究科学家Jim Fan第一时间对论文进行研究,之后发出了这样的感慨:“我们生活在这样一个时代:由非美国公司保持OpenAI最初的使命——做真正开放的前沿研究、为所有人赋能。”
他补充道:“DeepSeek-R1不仅开源了大量模型,还泄露了所有训练秘密。他们可能是第一个显示 RL(强化学习)飞轮发挥主要作用、持续增长的OSS项目。(对AI研究的)影响不仅可以通过‘内部实现了ASI’或‘草莓计划’等神话名称来实现,也可以通过简单地转储原始算法和matplotlib学习曲线来产生影响。”
Jim Fan的每一句话都在戳喜欢搞神秘,卖期货的OpenAI的肺管子。

图片来源:X
实际上,业界有这种看法的人还不少。Abacus ai的CEO Bindu Reddy评价道:“这是开源AGI的胜利,一家来自中国的小型初创公司击败了所有人”。
UC Berkeley教授Alex Dimakis也认为,DeepSeek现在已经处于领先位置,美国公司可能需要迎头赶上了。
Perplexity CEO Aravind Srinivas表更是直言:“DeepSeek才配叫做OpenAI。”
图片来源:X
除了对OpenAI的讽刺之外,Jim Fan还深入解读了R1模型的创新之处。
他表示,R1模型纯粹由RL驱动,完全没有SFT(“冷启动”)。这让人想起 AlphaZero——从头开始掌握围棋、将棋和国际象棋,而无需先模仿人类大师级的动作。
而且,R1使用由硬编码规则计算的真值奖励,避免使用任何RL容易攻击的学习奖励模型。随着训练的进行,模型的思考时间稳步增加。Jim Fan强调,这不是预先编程好的,而是一种模型自主的突发特性,并且模型也出现了自我反省和探索行为。
DeepSeek还使用了一种名为GRPO(组相对策略优化)的新优化方法,有效减少了内存使用。GRPO由DeepSeek于2024年2月发明。这也是为什么家用设备也能完整运行R1的原因。
基于此,有网友指出,鉴于Deepseek仍在使用GRPO等GPU性能较差的方法,可以推断出,该公司可能没有很多功能强大的Hopper GPU。这意味着,算力训练成本也是极低的。
有网友评价,这是AI的“顿悟时刻”:“R1-Zero(注:R1是R1-Zero调整后的模型)证明模型可以自我开发推理策略。举个例子:当遇到问题时,它学会了回溯并质疑其最初的假设——这是一种从未明确编程的行为。”这代表着DeepSeek的新模型已经能够具有像人类一样的自主学习能力了。
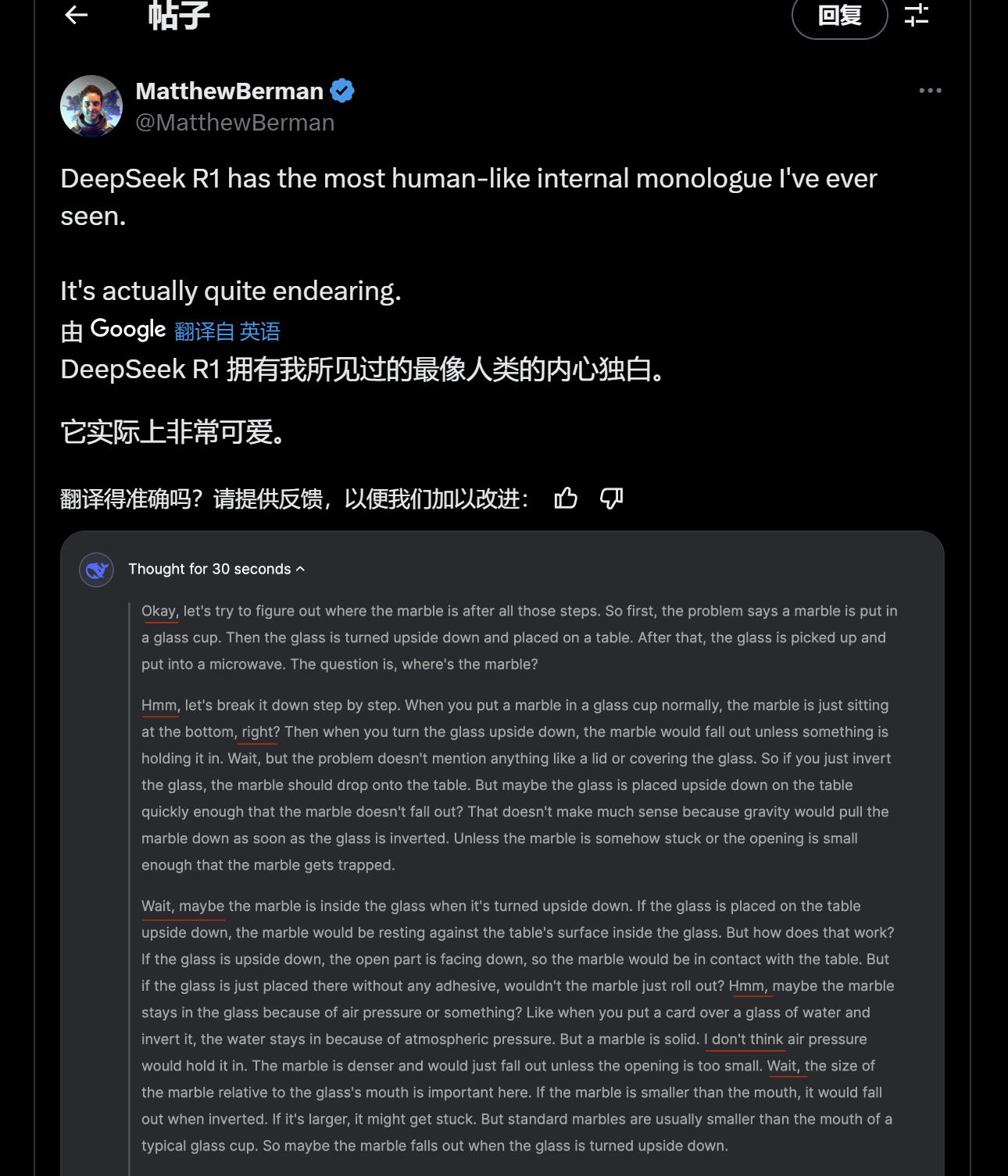
知名AI评测员Matthew Berman表示,R1拥有他所见过的最像人类的内心独白。
图片来源:X
然而,R1依然面临着开源模型V3一样的毛病。有网友向他提问谁训练你的时,它回答道:“我是被OpenAI开发的”。

图片来源:X

1本文为《每日经济新闻》原创作品。
2 未经《每日经济新闻》授权,不得以任何方式加以使用,包括但不限于转载、摘编、复制或建立镜像等,违者必究。











