◎ 截至5月16日,国内发布的305个大模型中约有六成尚未成功备案。一名大模型行业创业者告诉每经记者,没备案的大模型也不代表就消失在市面上。对于大模型的商业化,有行业人士认为,当下和未来两三年,大模型的商业探索会在成本和Token质量上相互妥协,并逐渐分化为两派。
每经记者|可杨 杨卉 每经编辑|兰素英
【编者按】:
本周,OpenAI推出新一代旗舰AI模型——GPT-4o。而早在2023年3月15日,GPT-4就已正式问世,其强大的文本生成能力迅速使生成式AI成为全球焦点,掀起了一场AI技术竞赛的浪潮。
在国内,生成式大模型的发布同样风起云涌。2023年3月16日,百度发布“文心一言”大模型;2023年4月10日,商汤科技的日日新发布;2023年4月11日,阿里巴巴的通义千问发布;2023年7月7日,华为云推出盘古大模型3.0……各方力量争先恐后,争奇斗艳,这股热潮被形象地称为“百模大战”。
那么,一年多过去了,国内大模型企业的发展现状如何?硅谷的生态又有怎样的新变化?在这一领域中,科技巨头和初创企业展现出了怎样的发展方向?对此,《每日经济新闻》特推出《“百模大战”周年考》策划,深入探讨这些问题。
一年前的3月15日,随着OpenAI多模态预训练大模型GPT-4的发布,国内包括百度、华为、腾讯等科技巨头,百川智能等初创企业,以及智谱AI研究院等研究机构纷纷扬帆起航,投身到人工智能(AI)大模型开发,试图搭上这趟时代的列车,轰轰烈烈的“百模大战”也由此开启。
据《每日经济新闻》记者的不完全统计,截至今年4月底,国内共计推出了305个大模型。而截至5月16日,只有约140个大模型完成生成式人工智能服务备案,占发布总量的45.9%。这意味着,还有约165个大模型尚未获得“过审”机会。
这一严峻现实的背后除了有技术层面的难度,还有训练和推理过程中高昂算力成本的制约;即便是跨过这一关,大模型企业如何实现商业化,依然着面临不小的难度。而对这场竞赛中可能被“出局”的公司来说,未来的路又在何方呢?
GPT-4的发布在全球掀起了“炼大模型”的热潮,面对这一新蓝海,科技巨头、初创企业以及科研院校相继开启布局,没人想错过这趟时代的列车。
据《每日经济新闻》不完全统计,截至今年4月底,国内共推出了约305个大模型,在过去一年推动着语言理解、图像识别等多个领域的技术进步。
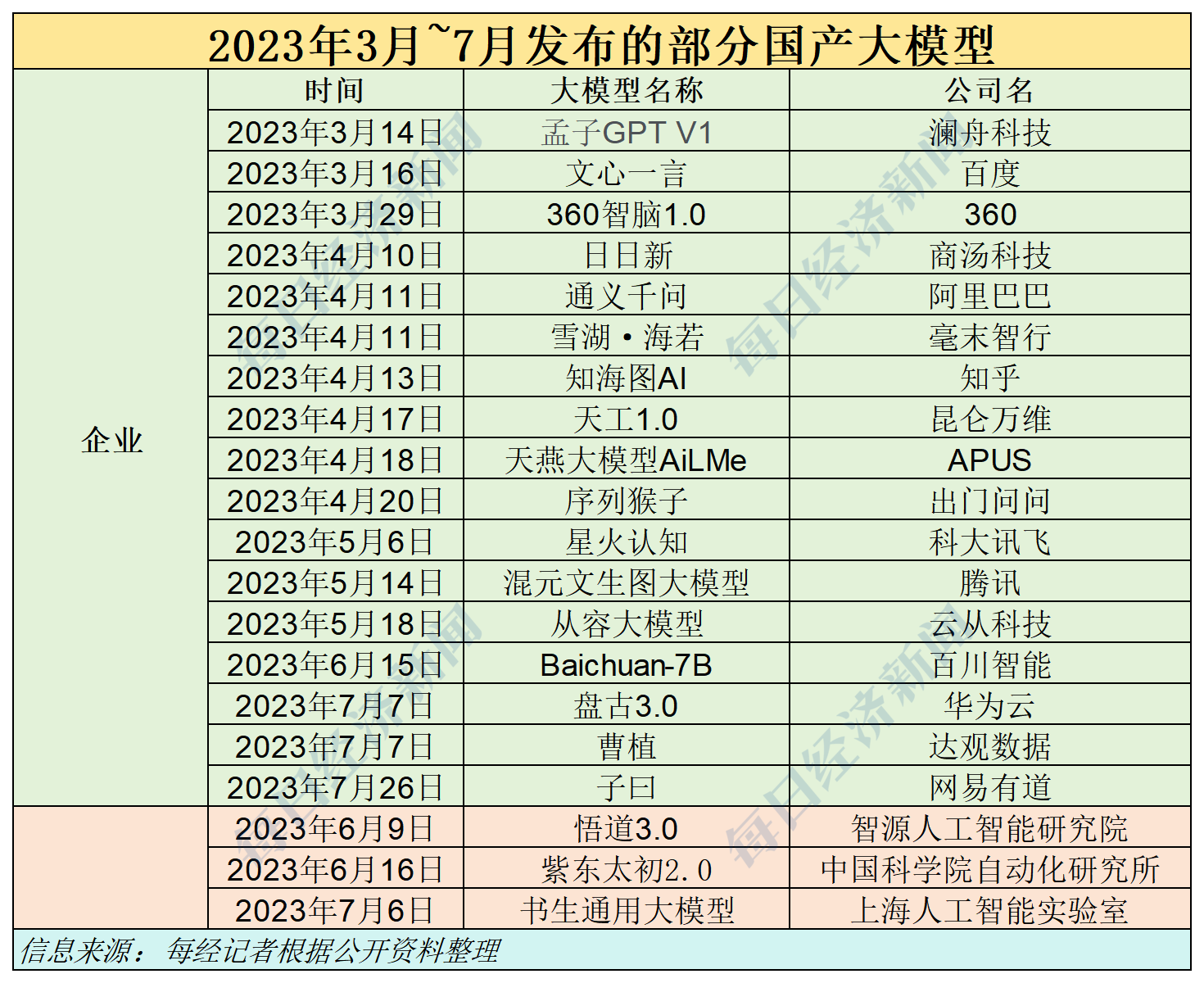
截至2024年5月16日,国内共有约140个大模型完成生成式人工智能服务备案,占305个大模型的45.9%左右。
此前,国家网信办有关负责人就《办法》相关问题回答媒体提问时介绍,《办法》规定,利用生成式人工智能技术向中华人民共和国境内公众提供生成文本、图片、音频、视频等内容的服务,适用本办法。
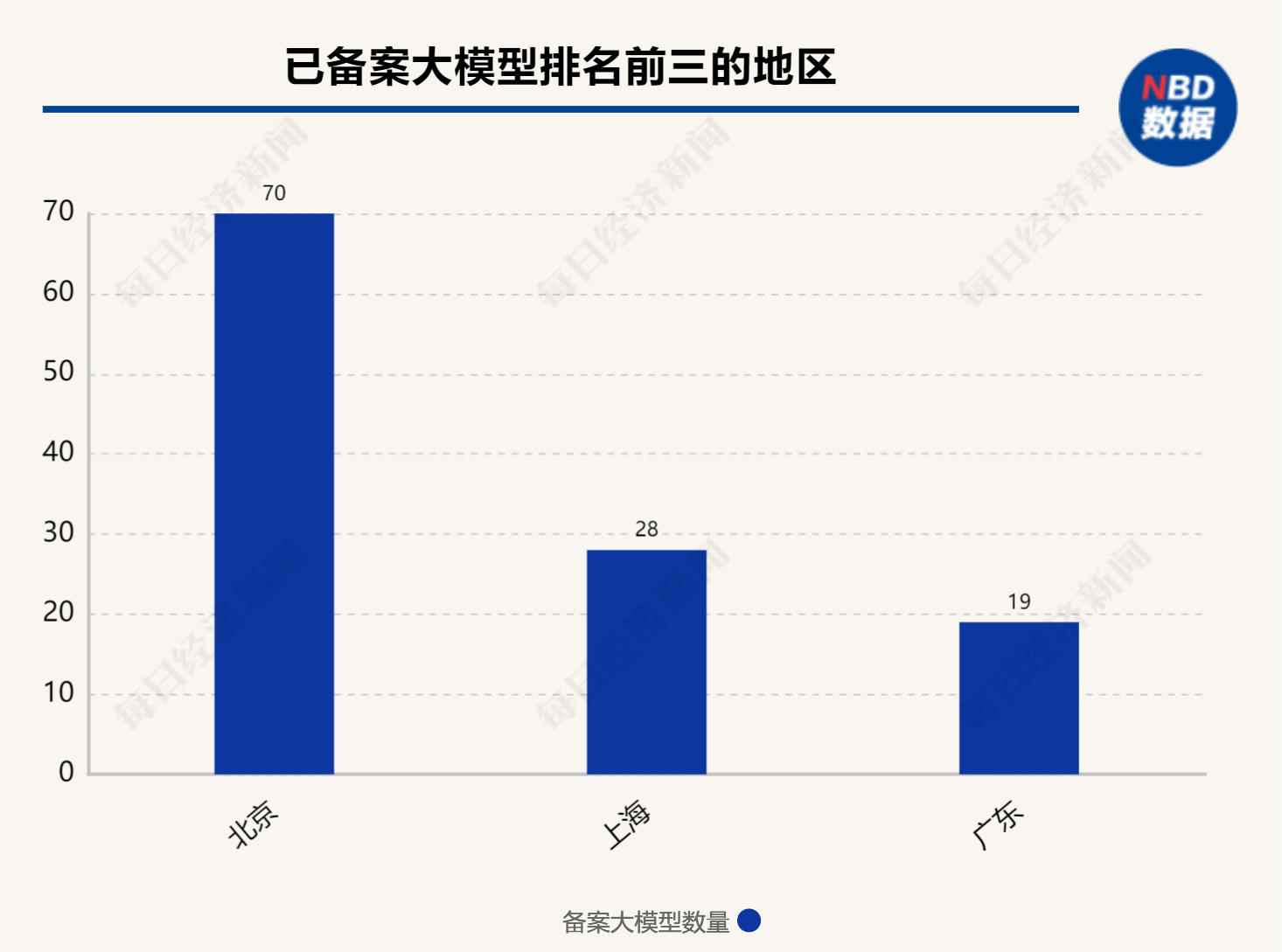
在已备案的大模型中,在地域分布上,北京以70个备案大模型领跑全国,凸显了其在AI领域的集聚效应。上海和广东紧随其后,分别有28个和19个模型备案。
而“140”这一数字同时也意味着,从备案层面来看,大约还有165个大模型依旧未通过备案,无法公开向公众提供服务。这些尚未能“过审”的大模型中,不乏一些备受关注的明星项目,包括曾号称是“国内首个ChatGPT”的元语智能大模型ChatYuan。
更多未完成备案的是“学院派”大模型。在305个大模型中,有60个大模型是由大学或研究院所研发。或许是由于研究机构的项目更偏重学术探索,而非商业应用,备案动力或流程可能不如企业迅速。也有大模型转向“境内深度合成服务算法”备案,例如恒生电子的大模型。
一名大模型行业创业者对《每日经济新闻》记者介绍称,当前模型相关的备案申请有点像专利申请,并不一定会通过,且申请周期较长,约在4~6个月。他表示,当下,大模型只要做To C服务,就需要备案,而在B端,一些大客户会要求大模型公司完成备案工作。
不过他同时强调,没备案的大模型也不代表就消失在市面上,很多来自研究所、大学的大模型仅仅只用于研究,就没有动机去完成备案。
一家大模型头部企业从业人士也告诉记者,来自大学的大模型,如果只做自己学术范围内的研究,是可以不用备案的。
“百模大战”行至此时,最终留下3~5家大模型已经成为行业对于这场竞赛最终结局的共识。“大模型这个行业(到最后)可能就不存在了,未来大模型就是几个最基本的底座,只有少数的几家公司。”行行AI董事长、顺福资本创始人李明顺曾在接受《每日经济新闻》记者采访时坦言。
算力资源的稀缺性是制约大模型发展的关键瓶颈。对不少大模型来说,没能挺过一周年,难搞的算力要负很大责任。对于模型厂商而言,目前主要的算力成本包括预训练成本和推理成本。模型推理应用阶段对算力的需求要远远高于训练阶段。
据中国工程院院士郑纬民计算,在大模型训练的过程中,70%的开销要花在算力上;推理过程中95%的花费也是在算力上。
以GPT-4为例,该模型的训练需要一万块英伟达A100芯片跑上11个月。假设每块A100的成本为10000美元(价格因供应商和购买数量而异),那么一万块A100的总成本约为1亿美元。
对于许多急匆匆踏上大模型赛道的创业公司或科技企业来说,在“烧”了一阵子钱后,他们绝望地发现,算力不仅越来越贵,质量也开始下降。
郑纬民表示,目前,市面上只有三类系统可支持大模型训练。其中,基于英伟达GPU的系统一卡难求;基于国产AI芯片的系统面临国产卡应用不足、生态系统有待改善的问题;而基于超级计算机的系统,虽然可在作好软硬件协同设计的情况下实现大模型训练,但需在超算机器尚未饱和的前提下操作,私人企业获得超算设备的机会并不大。
据英特尔方面介绍,在大模型领域,去年关注点更多是在模型训练上,对成本和功耗并不那么重视,彼时,企业都希望能训练一个自己的通用大模型。随着很多通用大模型被训练出来,今年关注的重点则转移到了推理。对企业来说,大模型训练出来是需要变现且能够盈利的。但目前市场上很多大模型都是基于开源的,性能差不多,用于训练的数据也差不多,很难通过差异化来盈利。
没有足够的资金支撑推理过程,成了很多创业者败退的原因之一。为了降低成本,部分企业正在尝试探索是否可以用CPU来做大模型推理。从当前一些案例来看,在130亿参数以下的大模型中,CPU是可以做到的这一点的。
然而,即便是熬过了推理关,企业要将大模型变现仍有不小的难度。在行云集成电路创始人季宇看来,大模型的商业落地与早期互联网时代相比区别很大,边际成本仍然非常高。大模型每增加一个用户,基础设施需增加的成本是肉眼可见的,一个月几十美元的订阅费用根本不足以抵消背后高昂的成本。
更为关键的是,眼下大模型要大规模商业化,在模型质量、上下文长度等方面还有进一步诉求,不排除会进一步增加边际成本。目前来看,日活千万的通用大模型一年需超过100亿元的收入才能支撑其背后的数据中心成本,未来大模型要像互联网产业一样服务上亿人,成本一定是迈不过去的槛。
如果说“百模大战”最后的赢家只属于少数几家公司,那在这场赛事中被淘汰的公司,未来会走向何方?
昆仑万维董事长方汉曾在接受《每日经济新闻》记者采访时表示,“百模大战”会淘汰一部分公司,剩下的科技公司肯定会继续全速前进。
在行云集成电路创始人季宇看来,当下和未来两三年,大模型的商业探索会在成本和Token质量上相互妥协,并逐渐分化为两派。
一派是质量优先,用高端系统打造高质量的通用大模型,寻找超级应用来覆盖高昂的成本。另一派是成本优先,用足够便宜的硬件提供基本够用的Token质量,寻找垂直场景的落地。若能在同样的成本下买到规格大得多的芯片,跑一个百亿千亿模型,支持超长上下文,商业化的空间会比今天大得多,就像曾经的显卡和游戏行业一样。
启明创投合伙人周志峰认为,当下,绝大多数的大模型企业是包着大模型的皮,裹着应用的心,“拥有模型能力的团队更容易在算法、模型、数据、模型的加速方面去做优化,以达到体验更好的产品,尤其对比那些用第三方模型纯粹做应用的公司。这一类公司其实不是模型公司,未来一定会是一家应用公司”。
周志峰以字节跳动为例,从今日头条到抖音到TikTok,背后的轴是AI驱动的推荐引擎。“字节跳动第一轮、第二轮融资的时候跟我们投资人讲得更多的故事是AI驱动的推进引擎,而今天不会再去说字节跳动是一家AI技术公司,只会记得是哪几个应用造成了这么大的规模。”同理,今天大部分的大模型公司未来也一定是靠它最终闯出了超级应用,大家因为这个超级应用而记住这家公司。
李明顺也持同样的观点,即不远的未来,有一部分大模型公司要转型成应用公司,因为大模型领域不需要这么多公司,“有一些大模型公司的创始人有Plan A和Plan B的双计划,就是一旦我的模型实在是拼不过前面的5家之后,就要被迫在一些垂直领域里面找到生存之地,它就会转型为一家应用公司。”
在备案成功的大模型中,部分模型已经从通用型转变为聚焦特定领域或行业的细分垂类模型。
中科闻歌董事长王磊在接受《每日经济新闻》记者采访时坦言,在过去的半年到一年内,适当做小行业大模型,降低参数规模的趋势已经变得非常明显。真正成功的商业应用不是制造一个巨无霸,而是能够被用户广泛使用且价格适中。“实用至上是关键,不必为了面子而去追求大规模,高昂的代价会影响产品的市场推广和用户的使用,实用性才是商业发展的主导原则。”
王磊表示,目前国内企业都意识到,最受欢迎的规模是70亿和130亿,300亿是单台推理的参数规模,比较受欢迎。“在我们的大模型发布时,国外网友评价这是企业级应用的小型参数规格。我认为一般的企业可能难以承受更大规模的产品。对于文本生成任务,这个规模基本上是足够的,但对于一些特定领域的任务,还需要强化模型的能力。”
第四范式也同样坚定选择投入行业大模型。“如果说无限把模型做大,往里面放无限多的数据,最后可能会达到AGI的状态,但是在每一个垂直应用,我们都要平衡好能力以及代价”。创始人戴文渊此前在第四范式的业绩沟通会上也表示,从技术的角度来说,第四范式也追求AGI,但是与此同时,“对于每一个客户的具体场景,我们也要做一定的裁剪,比如说这个考试只考数学,不一定需要让它有物理的能力。”

1本文为《每日经济新闻》原创作品。
2 未经《每日经济新闻》授权,不得以任何方式加以使用,包括但不限于转载、摘编、复制或建立镜像等,违者必究。











